
[DB] Oracle 정규표현식 사용하기
정규표현식
회사에서 DB에 데이터작업을 하다보면 데이터를 정제하는 일이 많다. 정확한 데이터를 가지고 서비스를 하기 위해서는 정규표현식이 굉장히 유용하였다.
정규표현식 종류
먼저 실습을 예로 들기전에 정규표현식 종류에 대해서 알아보자.
메타문자
- ^ : 문자열의 시작을 표현한다.
- $ : 문자열의 끝을 표현한다.
- \b : 단어의 경계. 문자열 시작과 끝, 공백, 개행, 탭, 콤마, 구두점, 대시문자 등이 올 수 있다.
- \s : 공백 문자 및 탭 문자에 매치한다.
- \S : 공백 문자가 아닌 한 글자에 매치한다.
- \w : 단어를 만들 수 있는 글자. 알파벳 대소문자, 숫자, 언더스코어를 포함한다. [A-Za-z0-9_] 와 같다.
- \W : \w에 포함되지 않는 문자들
수량한정자
- ? : 바로 앞의 글자 혹은 그룹이 1개 혹은 0개 이다.
*: 0개 이상이다.+: 1개 이상이다.- {n} : n 개가 있다.
- {n, m} : n개 이상, m개 이하가 있다.
오라클 정규표현식 종류
오라클 DB에 정규표현식으로 작업할때 주로 아래 함수를 사용한다.
- REGEXP_COUNT() : 패턴에 일치하는 문자열 갯수 카운트
- REGEXP_SUBSTR() : 문자열내에서 패턴에 일치하는 문자열을 추출
- REGEXP_REPLACE() : 문자열내에서 패턴에 일치하는 문자열을 다른 문자열로 대체
실제 업무에서 표준분류코드 정제하기
회사에서 공공기관에서 데이터를 받을때는 파일 단위로 몇백만 데이터를 적재한다. 예시를 위해서 표준분류코드 데이터를 입력하고 정제해보자!
우선 원천데이터를 적재할 테이블을 생성하자. 예시를 들기위해서 테이블명을 한글로 하였고, VARCHAR2(1000)을 들었다. 실제 회사에서는 저렇게 잘안잡는다.
CREATE TABLE 표준산업원천데이터 (
표준분류코드명 varchar2(1000)
);
Insert 문으로 데이터를 입력해보자. 데이터는 표준산업분류코드를 예시로 들었다.
INSERT INTO 표준산업원천데이터(표준분류코드명) VALUES ('A 농업, 임업 및 어업');
INSERT INTO 표준산업원천데이터(표준분류코드명) VALUES (' A01 농업');
INSERT INTO 표준산업원천데이터(표준분류코드명) VALUES (' A011 작물 재배업');
INSERT INTO 표준산업원천데이터(표준분류코드명) VALUES ('C 제조업');
INSERT INTO 표준산업원천데이터(표준분류코드명) VALUES (' C10, C11, C12 식료품 제조업, 음료 제조업');
COMMIT;
정제된 데이터를 넣기 위한 테이블도 구성해보자.
CREATE TABLE 표준산업분류코드 (
표준분류코드 varchar2(1000),
표준분류명 varchar2(1000),
표준분류구분 varchar2(1000)
);
데이터 정제
표준분류코드명이 입력한 데이터에서 표준분류코드(A, A01, C10, C11...), 표준분류명(농업, 임업 및 어업...), 표준분류구분(들여쓰기에 따라서 들여쓰기가 되어있을때마다 소분류로 구분)로 나눠야한다.
정규표현식을 써보자.
정규표현식으로 데이터 정제
/* 정규표현식으로 데이터 입력 */
SELECT REGEXP_SUBSTR(REGEXP_REPLACE(표준분류코드명, '\s'), '[A-Z][0-9]+(\,[A-Z][0-9]+)+|[A-Z][0-9]+|[A-Z]') AS 표준분류코드,
REGEXP_REPLACE(REGEXP_REPLACE(표준분류코드명, '\s'), '[A-Z][0-9]+(\,[A-Z][0-9]+)+|[A-Z][0-9]+|[A-Z]') AS 표준분류명,
CASE WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) IS null THEN '대'
WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) = 2 THEN '중'
WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) = 4 THEN '소' ELSE NULL END AS 표준분류구분
FROM 표준산업원천데이터;
하나씩 살펴보자
REGEXP_SUBSTR(REGEXP_REPLACE(표준분류코드명, '\s'), '[A-Z][0-9]+(\,[A-Z][0-9]+)+|[A-Z][0-9]+|[A-Z]')
- [A-Z][0-9]+(\,[A-Z][0-9]+)+ : 앞에 연속된 영문문자열 + 숫자를 컴마기준으로 추출하기 위한 정규표현식이다. 예를들어 ({C10, C11, C12}) 을 데이터로 추출한다.
- [A-Z][0-9]+ : 영문문자열 + 숫자를 추출한다. 뒤에 +가 붙은이유는 연속된 숫자가 있을 경우를 체크한다. (A1 or A01)
- (\,[A-Z][0-9]+) + : 콤마(,) 뒤에 다시한번 영문문자열 + 숫자를 추출한다. 뒤에 + 가 붙은경우는 연속된 컴마가 있을경우를 체크한다.
[A-Z][0-9]+|[A-Z]: 영문문자열 + 숫자의 경우와 영문문자열만 있을 경우를 추출하기 위한 정규표현식이다.
두 정규식을 | 기준으로 합치면 표준분류코드로 분류할 수 있다.
- REGEXP_REPLACE로 공백을 제거하고 REGEXP_SUBSTR로 위 정규표현식을 사용하면 원하는 결과값을 추출할 수 있다.
REGEXP_REPLACE(REGEXP_REPLACE(표준분류코드명, '\s'), '[A-Z][0-9]+(\,[A-Z][0-9]+)+|[A-Z][0-9]+|[A-Z]') AS 표준분류명,
- 표준분류명을 구분하는건 더 쉽다. 위 정규식을 그대로 이용하여 REGEXP_REPLACE() 함수만 사용하면 끝!
CASE WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) IS null THEN '대'
WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) = 2 THEN '중'
WHEN LENGTH(REGEXP_SUBSTR(표준분류코드명,'^\s+')) = 4 THEN '소' ELSE NULL END AS 표준분류구분
- 앞에 공백의 길이를 체크해서 표준분류 구분을 체크하면된다.
^\s+의 정규식은 맨 앞의 공백을 체크하는 정규표현식이다.
결과
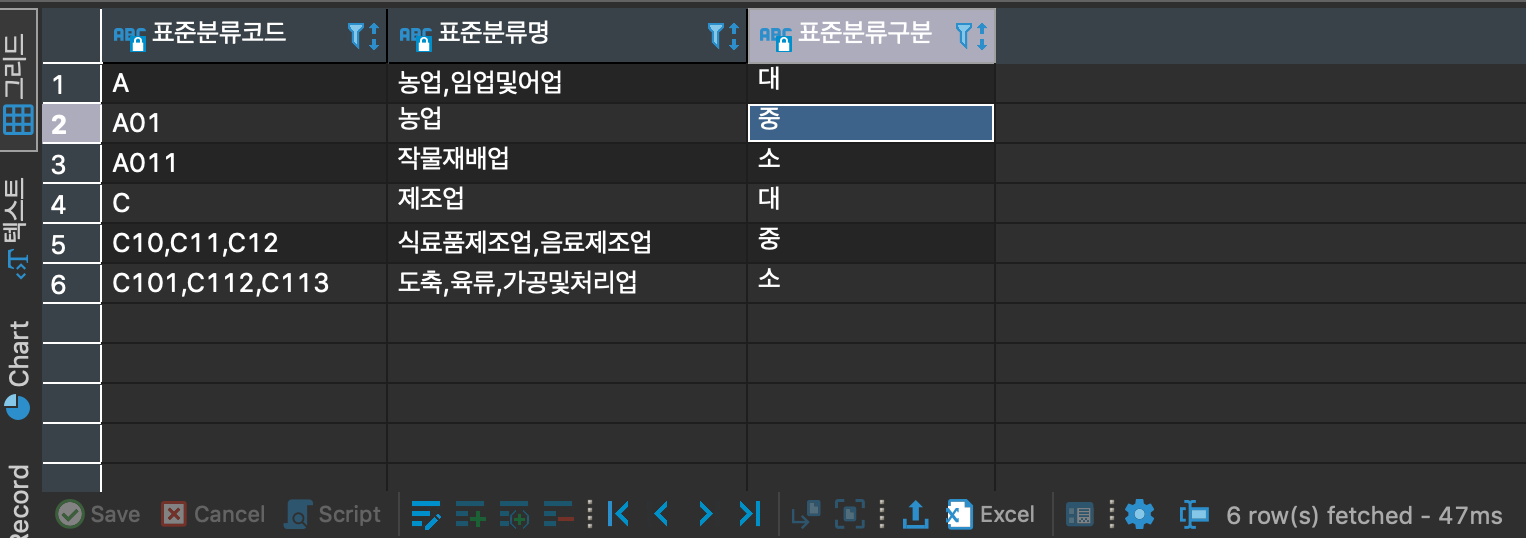
참조
오라클 정규식, 정규표현식(Regular Expression) 이란? 그리고 사용방법. 정규표현식의 개념과 기초 문법